E資格の受験資格を得るために必要な日本ディープラーニング協会認定講座であるラビットチャレンジの中で出題される演習問題をベースに、E資格の深層学習パートの解説と例題をまとめました。
今回の記事では、E資格範囲の後半部分に出てくる応用的な部分をまとめていきます。
試験範囲の前半部分は以下のリンクに記載してあります。
- RNN (Recurrent Neural Network)
- LSTM
- GRU (Gated Recurrent Unit)
- 双方向RNN
- Seq2Seq
- Word2vec
- Attention Mechanism
- 強化学習
- AlphaGo
- 軽量化・高速化技術
- 応用モデル
- Transformer
- 物体検出・セグメンテーション
- Seq2seq
- Transformer
- 最後に
RNN (Recurrent Neural Network)
RNNとは、再帰的なつながりを持つネットワークで、自然言語や時系列データなどの連続性を持つデータに対して良く用いられます。
RNNのアーキテクチャは、以下の図の左側または、それを分解した右側のグラフで示されますが、どちらも同じことを意味しています。

上のグラフを数学的に表すと以下の様になります。
RNNの再帰部分の数学的表記(ベクトル)
RNNの再帰部分のPython表記
変数や関数の定義が足りていないため以下のコード単体で実行できるものではありませんが、上述の数学表記は以下の様にPythonで実装することが出来ます。
※バイアスは[w_0}]として重み行列に含まれているものとします。
u[:, t+1] = np.dot(x, W_in) + np.dot(z[:, t].reshape(1, -1), W) z[:, t+1] = sigmoid(u[:, t+1]) y[:, t] = sigmoid(np.dot(z[:, t+1].reshape(1, -1), W_out)
Q1
RNNのネットワークには大きく分けて以下の3つの重みがあります。以下にそのうちの2つを示しました。残り1つの重みを説明してみてください。
- 入力から現在の中間層を定義する際に乗算される重み
- 中間層から出力層を定義する際に乗算される重み
- ?
解答例
回答は、中間層から次の中間層に再帰的に乗算される重みです。
Q2
以下は、RNNにおいて構文木を入力として再帰的に分全体の表現ベクトルを得るPythonスクリプトです。
ただし、_activation関数は何らかの活性化関数であり、気構造は再帰的な辞書で定義されているとします。
■に当てはまるコードを選んでみてください。
- (1) W.dot(left + right)
- (2) W.dot(np.concatenate([left, right])
- (3) W.dot(left * right)
- (4) W.dot(np.maximum(left, right))
def traverse(node): ''' node: tree node, recursive dict, {left: node, right: node} if leaf, word embedded vector, (embed_size,) W: weights, global variable, (embed_size, 2*embed_size) b: bias, global variable, (embed_size,) ''' if not isinstance(node, dict): v = node else: left = traverse(node['left']) right = traverse(node['right']) v = _activation(■) return v
解答例
答えは、(2)です。
隣接単語を表す表現ベクトル2つから1つの表現ベクトルを作るという処理は、隣接している表現ベクトルleftとrightを結合して重みを掛けることで実現されます。
def traverse(node): ''' node: tree node, recursive dict, {left: node, right: node} if leaf, word embedded vector, (embed_size,) W: weights, global variable, (embed_size, 2*embed_size) b: bias, global variable, (embed_size,) ''' if not isinstance(node, dict): v = node else: left = traverse(node['left']) right = traverse(node['right']) v = _activation(W.dot(np.concatenate([left, right]) return v
BPTT (Backpropagation Through Time)
RNNの再帰的なネットワークに対して誤差逆伝播を行うための手法としてBPTTと呼ばれる方法があります。
以下のグラフにて表すことができます。

BPTTのパラメータ更新
BPTTの再帰部分
したがって、RNNの再帰部分は以下の様にして前の時系列からの次の時系列への勾配の更新が行われます。
Q3
なお、中間層の出力にはシグモイド関数を作用させてください。
解答例
解答は以下の通りです。
バイアスには適当な文字を割り当てています。
LSTM
RNNの課題として、BPTTにて時系列を遡るほど勾配が消失していくために長い時系列の学習が困難という点があります。
逆に、学習率に大きな値を使用したり、活性化関数に恒等関数を使ったりした場合には時系列を遡るほど勾配が指数関数的に大きくなり損失関数の最小値がいつまでも収束しないという勾配爆発が起きることもあります。

Q4
勾配爆発を防ぐための手法として、勾配クリッピングと呼ばれる手法があります。勾配のノルムが閾値を超えた際に勾配のノルムを閾値に正規化するという仕組みになっています。
以下の勾配クリッピングの関数において、■に当てはまるコードを以下の4つから選んでみてください。
- (1)
grad * rate - (2)
grad / norm - (3)
grad / threshold - (4)
np.maximum(grad, threshold)
def gradient_clipping(grad, threshold): ''' grad: gradient ''' norm = np.linalg.norm(grad) rate = threshold / norm if rate < 1: return ■ return grad
解答例
答えは(1)です。
ノルムがthresholdを超えた際に、ノルムがthresholdぴったしになるようにベクトルの要素を小さくしてあげるという処理になっています。
def gradient_clipping(grad, threshold): ''' grad: gradient ''' norm = np.linalg.norm(grad) rate = threshold / norm if rate < 1: return grad * rate return grad
CEC (Constant Error Crousel)
LSTMでは、RNNの学習機能と前の情報を記憶する機能を分離し、記憶する機能をCECに保持させています。
時系列的な勾配が1となれば、つまり、以下の式を満たすことができれば勾配消失および勾配爆発を防ぐことが出来ます。
※ 上式で示す時系列的な重み更新については、BPTTの再帰部分で説明済みです。
CECが持っていない学習機能は、入力ゲートと出力ゲートという部分が持っています。
入力ゲート
CECに記憶させる方法を学習します。
今回の入力値と前回の出力値をもとに今回の入力を記憶させる方法を決めます。
LSTMのアーキテクチャでいう所のは、今回の入力をどれくらい使うか、
は、前回の出力をどれくらい使うかということを学習していきます。
出力ゲート
CECに記憶を出力させる方法を学習します。
入力ゲートと同様、今回の入力値と前回の出力値をもとに今回の入力を記憶させる方法を決めます。
LSTMのアーキテクチャでいう所のは、今回の入力をどれくらい使うか、
は、前回の出力をどれくらい使うかということを学習していきます。
ここまでで、学習しながら過去の情報を記憶できるようになりましたが、このままではいつまでも古い情報が削除されずに保管され続けます。
そこで古い情報の削除を行うのが忘却ゲートです。
Q5
以下のコードは、LSTMの順伝播を行うPythonスクリプトです。ただし、_sigmoid関数は要素ごとにシグモイド関数を作用させる関数とします。
■に当てはまるコードを以下の4つから選んでみてください。
- (1)
output_gate * a + forget_gate * c - (2)
forget_gate * a + output_gate * c - (3)
input_gate * a + forget_gate * c - (4)
forget_gate * a + input_gate * c
def lstm(x, prev_h, prev_c, W, U, b): ''' x: inputs, (batch_size, input_size) prev_h: outputs at the previous time step, (batch_size, state_size) W: upward weights, (4*state_size, input_size) U: lateral weights, (4*state_size, state_size) b: bias, (4*state_size,) ''' lstm_in = _activation(x.dot(W.T) + prev_h.dot(U.T) + b) a, i, f, o = np.hsplit(lstm_in, 4) a = np.tanh(a) input_gate = _sigmoid(i) forget_gate = _sigmoid(f) output_gate = _sigmoid(o) c = ■ h = output_gate * np.tanh(c) return c, h
解答例
答えは、(3)です。
新しいセルの状態は、セルへの計算された入力に入力ゲートを掛け合わせたものと、1ステップ前のセルの状態に忘却ゲートを掛け合わせたものの和として表現されます。
def lstm(x, prev_h, prev_c, W, U, b): ''' x: inputs, (batch_size, input_size) prev_h: outputs at the previous time step, (batch_size, state_size) W: upward weights, (4*state_size, input_size) U: lateral weights, (4*state_size, state_size) b: bias, (4*state_size,) ''' lstm_in = _activation(x.dot(W.T) + prev_h.dot(U.T) + b) a, i, f, o = np.hsplit(lstm_in, 4) a = np.tanh(a) input_gate = _sigmoid(i) forget_gate = _sigmoid(f) output_gate = _sigmoid(o) c = input_gate * a + forget_gate * c h = output_gate * np.tanh(c) return c, h
覗き穴結合 入力ゲートや出力ゲートと違って、CEC自身の値を重み行列を介して伝播可能にした構造です。
GRU (Gated Recurrent Unit)
LSTMでは、パラメータ数が多すぎて計算負荷が大きいという問題を解決するために生まれた手法です。

Q6
LSTM全体の課題について、簡潔に答えてみてください。
解答例
LSTMは、パラメータ数が多く計算コストが大きいことが課題になっています。
Q7
以下のコードは、GRUの順伝播を行うPythonスクリプトです。ただし、_sigmoid関数は要素ごとにシグモイド関数を作用させる関数とします。
■に当てはまるコードを以下の4つから選んでみてください。
- (1)
z.dot(h_bar) - (2)
(1-z).dot(h_bar) - (3)
z.dot(h).dot(h_bar) - (4)
z.dot(h_bar) + (1-z).dot(h)
def gru(x, h, W_r, U_r, W_z, U_z, W, U): ''' x: inputs, (batch_size, input_size) h: outputs at the previous time step, (batch_size, state_size) W_r, U_r: weights for reset gate W_z, U_z: weights for update gate U, W: weights for new state ''' r = _sigmoid(x.dot(W_r.T) + h.dot(U_r.T)) z = _sigmoid(x.dot(W_z.T) + h.dot(U_z.T)) h_bar = np.tanh(x.dot(W.T) + (r * h).dot(U.T)) h_new = ■ return h_new
解答例
答えは(4)です。
新しい中間状態は1ステップ前の中間表現と計算された中間表現の線形和で表現されます。
def gru(x, h, W_r, U_r, W_z, U_z, W, U): ''' x: inputs, (batch_size, input_size) h: outputs at the previous time step, (batch_size, state_size) W_r, U_r: weights for reset gate W_z, U_z: weights for update gate U, W: weights for new state ''' r = _sigmoid(x.dot(W_r.T) + h.dot(U_r.T)) z = _sigmoid(x.dot(W_z.T) + h.dot(U_z.T)) h_bar = np.tanh(x.dot(W.T) + (r * h).dot(U.T)) h_new = z.dot(h_bar) + (1-z).dot(h) return h_new
双方向RNN
過去のステップの情報だけでなく、未来のステップの情報を加味することで精度を向上させたRNNモデルのことです。
機械翻訳などで用いられています。

Q8
以下のコードは、双方向RNNの順伝播を行うPythonスクリプトです。ただし、_rnn関数はRNNの順伝播を表し中間層の系列を返す関数であるとします。
■に当てはまるコードを以下の4つから選んでみてください。
- (1)
h_f + h_b[::-1] - (2)
h_f * h_b[::-1] - (3)
np.concatenate(h_f, h_b[::-1]], axis=0) - (4)
np.concatenate(h_f, h_b[::-1]], axis=1)
def bidirectional_rnn_net(xs, W_f, U_f, W_b, U_b, V): ''' W_f, U_f: forward RNN weights, (hidden_size, input_size) W_b, U_b: backward RNN weights, (hidden_size, input_size) V: output weights, (output_size, 2*hidden_size) ''' xs_f = np.zeros_like(xs) xs_b = np.zeros_like(xs) for i, x in enumerate(xs): xs_f[i] = x xs_b[i] = x[::-1] hs_f = _rnn(xs_f, W_f, U_f) hs_b = _rnn(xs_b, W_b, U_b) hs = [■ for h_f, h_b in zip(hs_f, hs_b)] ys = hs.dot(V.T) return ys
解答例
答えは(4)です。
双方向RNNでは、順方向と逆方向に伝播した時の中間層表現を結合したものが特徴量となります。
コメントに記載されたVのサイズからも横方向に結合するべきことが分かります。
def bidirectional_rnn_net(xs, W_f, U_f, W_b, U_b, V): ''' W_f, U_f: forward RNN weights, (hidden_size, input_size) W_b, U_b: backward RNN weights, (hidden_size, input_size) V: output weights, (output_size, 2*hidden_size) ''' xs_f = np.zeros_like(xs) xs_b = np.zeros_like(xs) for i, x in enumerate(xs): xs_f[i] = x xs_b[i] = x[::-1] hs_f = _rnn(xs_f, W_f, U_f) hs_b = _rnn(xs_b, W_b, U_b) hs = [np.concatenate([h_f, h_b[::-1]], axis=1) for h_f, h_b in zip(hs_f, hs_b)] ys = hs.dot(V.T) return ys
Seq2Seq
Seq2Seqとは、Encoder-Decoderモデルの1種であり、日本語文などの入力をベクトル表現にエンコードし、そのベクトル表現を英語文などの出力へデコードするといった働きをします。
過去の文の出力から文脈を意識して次の文を出力するといったことはできません。
Encoder RNN
Seq2SeqのEncoder部分は大きく分けて以下の2つの機能からなります。
Taking
文章を単語などのトークンに分割し、それぞれのトークンにIDを割り当てOne-hotベクトルへ変換します。
このとき、1万のトークンに分割されていれば、One-hotベクトルの要素数は1万となります。
Embedding
One-hotベクトルの各要素を、トークンそれぞれの意味が似ている要素を集約していくような考え方でRNNによって分散表現ベクトルを得ます。
このとき、分散表現ベクトルの要素数は数百程度になっています。
Decoder RNN
RNNのデコーダ部分では、分散表現ベクトルを入力として文などの出力します。
Sampling
生成確立に基づいて、トークンをランダムに選びます。
Embedding
選んだトークンをEmbeddingしてDecoder RNNへの次の入力とすることを繰り返し、トークンを文字列へ変換します。
Q9
以下の選択肢から、seq2seqについて説明しているものを選んでみてください。
- (1) 時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
- (2) RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
- (3) 構文木などの機構増に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
- (4) RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
解答例
答えは(2)です。
問題の項目は、それぞれ以下の内容に関連しています。
- (1) 双方向RNN
- (2) seq2seq
- (3) 構文木
- (4) LSTM
Q10
機械翻訳タスクにおいて、入力は複数の単語からなる文(文章)であり、それぞれの単語はone-hotベクトルで表現されています。
Encoderにおいて、それらの単語は単語埋め込み(Embedding)により特徴量に変換され、RNNによって時系列の情報を持つ特徴へエンコードされます。
以下に入力である文を時系列の情報を持つ特徴量へエンコードする関数をPythonで記載しました。ただし、_activation関数は何らかの活性化関数を表すとします。
■に当てはまるコードを選択してみてください。
- (1)
E.dot(w) - (2)
E.T.dot(w) - (3)
w.dot(E.T) - (4)
E * w
def encode(words, E, W, U, b): ''' words: sequence words (sentence), one-hot vectors, (n_words, vocab_size) E: word embedding matrix, (embed_size, vocab_size) W: upward weights, (hidden_size, hidden_size) U: lateral weights, (hidden_size, embed_size) b: bias, (hidden_size,) ''' hidden_size = W.shape[0] h = np.zeros(hidden_size) for w in words: e = ■ h = _activation(W.dot(e) + U.dot(h) + b) return h
解答例
答えは、(1)です。
wordsは、one-hotベクトルであるw毎に取り出され、埋め込み行列Eとの内積(単語埋め込み)により、別の特徴量へ変換されます。
def encode(words, E, W, U, b): ''' words: sequence words (sentence), one-hot vectors, (n_words, vocab_size) E: word embedding matrix, (embed_size, vocab_size) W: upward weights, (hidden_size, hidden_size) U: lateral weights, (hidden_size, embed_size) b: bias, (hidden_size,) ''' hidden_size = W.shape[0] h = np.zeros(hidden_size) for w in words: e = E.dot(w) h = _activation(W.dot(e) + U.dot(h) + b) return h
HRED
seq2seqとContext RNN合わせた手法であり、過去n-1個の文の出力から次の出力を生成します。
例:
- 「インコかわいいよね」
- 「うん」
- 「インコかわいいの分かる」
seq2seqでエンコーダの出力として得られる分散表現ベクトルを、さらに別のseq2seqへ渡すContext RNNによって隠れ層を過去の文脈を含むベクトルへ変換する構造になっています。
HREDの課題 確率的な生成が行われないため、同じコンテキストが与えられると毎回同じ文の出力が行われます。
また、「うん」「そうだね」といった短く情報量に乏しい文を出力しがちです。
HREDに対して潜在変数にN(0, 1)を仮定したVAEの概念を追加することで、確率的な出力を行うVHREDという手法になります。
Word2vec
分散表現を得るため手法としてword2vecというものが提案されてきました。
これは、先に述べているように疎なone-hotベクトルではなく密なベクトルとして特徴表現を得ることができる手法です。
Attention Mechanism
seq2seqは、長い文への対応が難しいという課題があり、例えば文が2単語からでも100単語から成っていても、固定次元ベクトルで表現される必要がありました。
そこで、文が長くなるほどシーケンスの内部表現の次元も大きくなっていくという、Attention Mechanismの仕組みを取り入れられました。
Q11
RNNとword2vec、seq2seq、Attentionの違いを簡潔に説明してみてください。
解答例
- RNN: 時系列データを処理するのに適したネットワーク
- word2vec: 文の分散表現ベクトルを得る方法
- seq2seq: 1つの時系列データから別の時系列データを得るネットワーク
- Attention: 時系列データの中身の内部表現の関連性に重みを与える方法
強化学習
強化学習とは、長期的に報酬を最大化できるように、環境の中で行動を選択できるエージェントを作るための機械学習分野です。
以下で示すイメージの様に、方策、状態、価値という3つの要素が存在しており、エージェントは状態に合わせて価値が高くなる方策を学習していきます。

価値関数
価値関数には主に以下の2種類があり、現在は行動価値関数Qが用いられています。
ゴールまで今の方策を続けたときの報酬の予測値として値が得られます。
- 状態価値関数
: 状態に応じて報酬を計算する
- 行動価値関数
: 状態と行動のセットに対して報酬を計算する
方策関数
- 方策関数
: ある状態でどのような行動をとるかを確率として与える関数
方策勾配法
得られる報酬が最大となるように、方策関数のパラメータを最適化する手法として、以下の方策勾配法があります。
ニューラルネットワークでは誤差を最小化するパラメータを求めましたが、強化学習では期待報酬を最大化するという目的で最適化を行います。
AlphaGo
Alpha Go (Lee)
Alpha Goの方策関数にはPolicyNet、価値関数にはValueNetと呼ばれるネットワークを使います。
囲碁の目は19×19の2次元であるため、両ネットワークではCNNが使われています。
PolicyNetは、次に打つべき目を確率で出力してくれます。
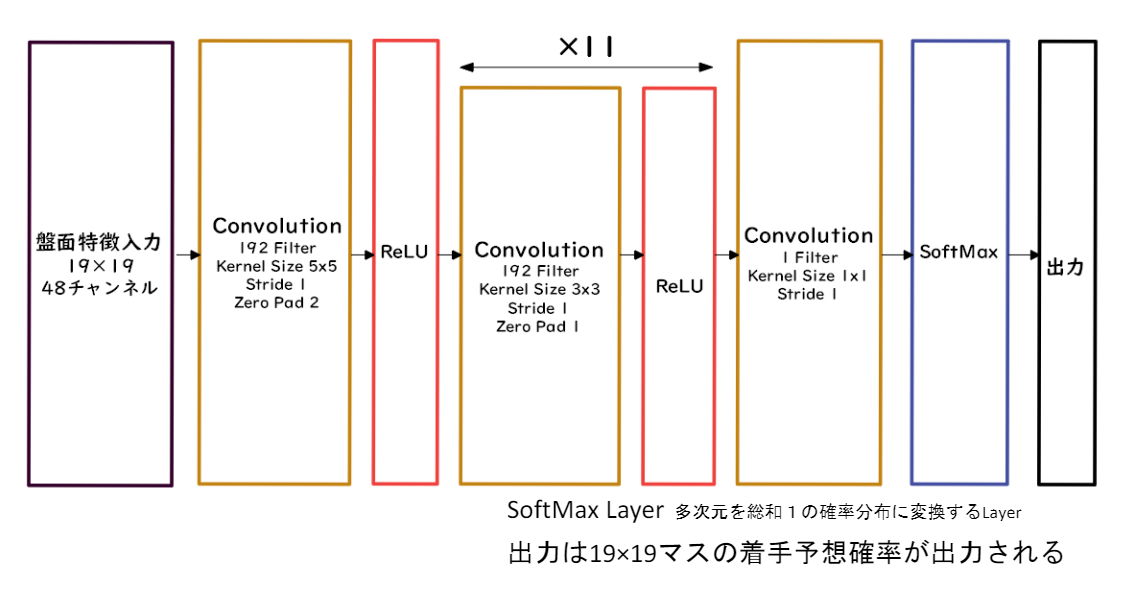
ValueNetは現局面の勝率を-1~1の間で表した値を出力してくれます。

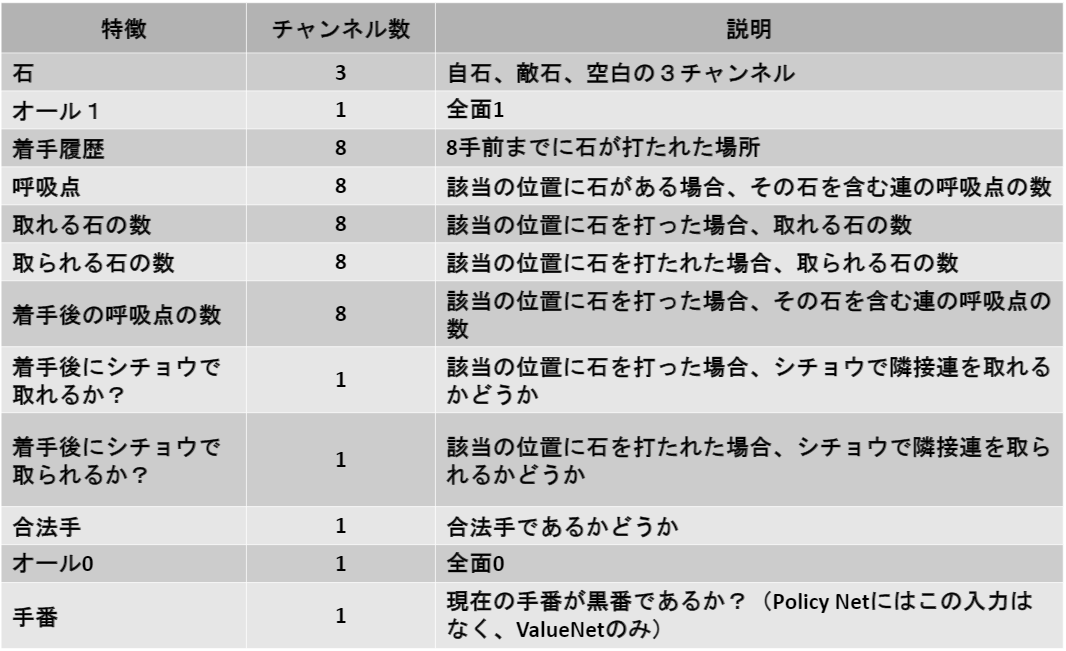
また、PolicyNetおよびValueNetへの入力はそれぞれ48チャネル、49チャネルとなっていますが、その内訳は以下の通りです。
学習ステップ
- 教師あり学習によるRollOutPolicyとPolicyNetの学習
- 強化学習によるPolicyNetの学習
- 強化学習によるValueNetの学習
RollOutPolicyは、ニューラルネットワークではなく線形関数であり、高速に学習を進めるために学習ステップの初期に利用されます。
Alpha Go Zero
AlphaGo (Lee)とAlpha Go Zeroに違いは以下の通りです。
- 教師あり学習を一切行わず、強化学習のみで作成
- 特徴入力からヒューリスティックな要素(人間が判断して特徴量を作成すること)を排除し、石の配置のみにした
- PolicyNetとValueNetを1つのネットワークに統合した
- ResidualNetを導入した
- RollOutシミュレーションをなくした
ResidualNetwork
ネットワークにショートカット構造を追加することで、勾配消失・勾配爆発を抑える効果を狙っています。これにより、100層を超えるネットワークでの安定した学習を可能としました。
軽量化・高速化技術
分散深層学習
データ並列化
データが大きい際に用いられる並列化です。
複数のワーカー(端末自体またはGPUなどの計算機)を用意して、分割したデータを各ワーカに計算させる方法です。
同期型データ並列化では、以下の図のように全ワーカーの計算終了を待ち、各ワーカの計算した勾配の平均を使って親モデルのパラメータを更新します。

非同期型データ並列化では、以下の図のように各ワーカーは自分の学習が終了するとモデルをサーバにプッシュします。新たに学習を始める際にはサーバから最新のモデルをポップして学習を始めます。

性能は、多くの場合で以下の関係性となります。
- 速度: 非同期型 > 同期型
- 安定性: 非同期型 < 同期型
- 精度: 非同期型 < 同期型
モデル並列化
モデルが大きい場合に用いられる並列化です。モデル並列化は、多くの場合、1台の端末上の複数GPU上で実行されます。
モデルの軽量化
量子化 (Quantization)
ネットワークが大きくなると大量のパラメータが必要となり、学習や推論に多くのメモリ、GPU/CPUを必要とします。
パラメータの64bit浮動小数点を32bitなどへ精度を落とす(32bitで量子化する)ことで、メモリ使用量と演算処理のコスト削減を行います。
量子化によって、モデルの表現力は低下することになるはずと思われますが、実際には64bit(倍精度)から32bit(単精度)にしてもほとんどモデルの精度は変わらないようです。
蒸留
- 教師モデル
- 大きなモデルやアンサンブルされたモデルなどの予測精度が高いモデル
- 生徒モデル
- 教師モデルをもとに作る軽量なモデル
学習済みの教師モデルの重みは固定したまま、教師モデルの出力と生徒モデルの出力の誤差(Soft target loss)と、正解ラベルと生徒モデルの出力の誤差(Hard target loss)を使って重みを更新してきます。
プルーニング
重みが閾値以下となったニューロンを削除して再学習を行うことで、モデルの軽量化および高速化を行うことが出来ます。
応用モデル
MobileNet
軽量で高速な画像認識のモデルです。
Depthwise Separable convolutionという手法で、畳み込み演算を以下の2つに分解して順に実行することで、一般的な畳み込みに比較して大幅に計算量とパラメータを削減します。
- Depthwise convolution: フィルタ数が1
- Pointwise convolution: カーネルサイズが1×1
カーネルのチャネル数は、1であっても入力マップのチャネル数Cであっても計算量は同じになります。
一般的な畳み込みの計算量は、以下の図で示すところのH×W×C×K×K×Mとなります。

Depthwise convolutionの計算量は、以下の図で示すところのH×W×C×K×Kとなります。

Pointwise convolutionの計算量は、以下の図で示すところのH×W×C×Mとなります。

計算量を表にまとめます。
| 手法 | 計算量 |
|---|---|
| 一般的な畳み込み | H×W×C×K×K×M |
| Depthwise separable convolution | H×W×C×K×K + H×W×C×M |
DenseNet
CNNの層が深くなるにつれて勾配消失や勾配爆発の問題により学習難しくなるという問題がありました。
この問題への対処となるResNetと似たアーキテクチャで、同じく問題対処が可能となるDenseNetというものが存在します。

DenseNetには、DenseBlockと呼ばれる部分があり、そこでは以下の図のように、出力層に前の層の入力をチャネルとして足し合わせることでチャネル数が成長率kずつ増えていきます(この例ではk=3)。

前の層の入力をチャネルとして足し合わせる部分は、以下の様にして実現されています。

上図のBatch正規化ついては、次の章Batch正規化で説明します。
DenseBlockを抜けると特徴マップのチャネル数が増えていくため、DenseBlockの次の層のConvolution層およびPooling層にて元のチャネル数までサイズを落とされます。
Batch正規化
Batch正規化
バッチ正規化では、同一チャネルのミニバッチ内のサンプルを平均0、分散1となるよう標準化する手法です。

- バッチ正規化の狙い
- 学習時間短縮
- 初期値への依存低減
- 過学習の抑制
- バッチ正規化の問題
- バッチサイズが小さい条件下では、学習が収束しないことがある
Layer正規化
ハードウェア性能が低い端末での実行時の様に、バッチサイズを小さくする必要がある場合には、バッチ正規化ではなくレイヤ正規化を用いることが出来ます。

- レイヤ正規化の特徴
- 結果がミニバッチサイズに依存しない
- 入力データのスケールに関してロバスト
- 重み行列のスケールやシフトに関してロバスト
Instance正規化
各サンプルの各チャネルで平均0、分散1となるよう標準化する手法です。バッチ正規化のバッチサイズが1の場合と同じ動きになります。

- インスタンス正規化の特徴
- 画像コントラストの正規化に寄与
- 画像のスタイル転送やテクスチャ合成タスクなどで利用される
WaveNet
Pixel CNNという画像生成モデルを音声に応用したものです。
通常の畳み込みではなく、Dialted convolutionが適用されます。
- 層が深くなるにつれて、畳み込むリンクを離す
- 受容野を簡単に増やすことが出来る

Transformer
物体検出・セグメンテーション
物体認識タスクには以下の4つのタスクが存在します。
- 分類 (Classification)
- 物体検出 (Object detection)
- 意味領域分割 (Semantic segmentation)
- 個体領域分割 (Instance segmentation)

データセット
代表的な画像データセットについて、クラス数を横軸に、Box/画像数(1枚あたりに含まれる検出対象)を縦軸にプロットしたものを以下にプロットすることが出来ます。

クラス数が大きいデータセットには、ノートパソコンの画像に対してLaptopとNotebookといった本来統一した1ラベルを与えるべきものが複数に分かれているものも存在しています。
目的に応じて適したデータセットを選択する必要があります。
評価指標
物体検出の評価指標には、confidenceとIoU (Intersection over Union)が存在します。
confidenceはクラス分類のタスクで用いられる評価指標と同じものです。
一方、IoUは、物体位置の予測精度を評価することが出来る指標です。
Ground-Truth BBと呼ばれる物体位置の正解を示す領域に対して、Predicted BBと呼ばれる物体位置予測の精度を評価します。

Unionを分母に取っている理由は、Ground-Truth BBとPredicted BBがどちらか一方に完全に包含されている場合を考えてみると理解できます。
例えば、Predicted BBを画像いっぱいに大きく取った場合、IoC定義の分母をUnionとしていなければ正しく予測できているとはとても言えない状況なのにIoCが最大値の1を取ってしまいます。
Precision/Recallの計算
以下の条件で評価した際のPrecisionおよびRecallについて画像で示します。
- 入力画像1枚に車、人、犬が含まれる
- confidenceの閾値=0.5, IoUの閾値=0.5

AP/mAP
RP曲線(Recall-Precision曲線)を積分することでAP(Average Precision)という単一のクラスに対する指標を算出することが出来ます。
Confidenceの大きい順に並べ、PR曲線をRecallに関する関数とみなしてPR曲線下側の面積を求めるという流れになっています。

mAP(mean Average Precision)は、複数クラスそれぞれにおいてAPを計算し、算術平均を取ったものです。
1段階検出器/2段階検出器
物体検知には、候補領域の検出とクラス推定を同時に行うか否かの2種類のやり方が存在しています。
それぞれの特徴と、代表的な物体検知フレームワークがそのどちらに属しているかを以下の画像にて示します。

SSD
SSDは、Default Boxと呼ばれるバウンディングボックスを始めに用意しておき、検知する物体に合わせてDefault Boxを移動/変形する手法です。

Poolingによって解像度を落とした特徴マップの要素1つ1つに対して、各クラスへの分類のconfidenceおよび、DefaultBoxからの位置/サイズのオフセットを出力とします。

特徴マップのConvolution+Poolingを経るにつれて解像度が落ちていくのは、画像サイズは同じでピクセルサイズが大きくなっているイメージになります。解像度が落ちていくにつれて、大きな物体の検出が行われていきます。
Semantic segmentation
Semantic segmentationではPoolingで解像度を落としていった後に、解像度を上げてセグメンテーションを行う必要があります。
そもそも解像度を下げている理由は、受容野を広げるためです。狭い受容野では(猫の腕の一部を見ても犬の腕と見分けがつかないのと同じように)、物体の特徴を捉えることが難しくなるため受容野を広げる必要があったということです。
また、通常のConvolutionよりも解像度を落とさずに受容野を広げることが出来る畳み込みとしてWaveNetでも使われていたDilated convolutionを用いることが出来ます。
解像度を上げるために、Deconvolution/Transposed convolutionが行われます。

Poolingにより失われた輪郭情報については、畳み込みが進む前の出力を加えるelement-wise additionなどの手法によって補完します。
Seq2seq
系列(Sequence)を入力として、系列を出力するものであり、Encoder-Decoderモデルとも呼ばれています。

以下のような場面で使われています。
- 翻訳(日本語⇒英語)
- 音声認識(波形⇒テキスト)
- チャットボット(テキスト⇒テキスト)
seq2seqの問題点として入力系列を1つのベクトルで表現しているために、入力系列が長くなると表現力が足りなくなり精度が落ちるという点があります。

Encoder
上の英語翻訳の例でEncoderを説明します。
日本語を入力としてバッチ内の系列の長さを固定長としてPaddingを加え、系列内の各時点の単語の次に続く単語の予測/生成を以下の様に行います。

しかし、実際にEncoderの結果で活用するのは予測結果ではなく、内部状態ベクトルです。
内部状態ベクトルは、Decoderへの入力として渡されます。
Decoder
Decoderは、Encoderからの入力として内部状態ベクトルを受け取る以外は、上で説明した「次の単語を予測する」普通のRNNです。
時刻tの入力単語の予測結果
が時刻t+1の入力として用いられるため、予測が間違っていた場合に後ろの時刻の予測では入力自体が間違っていることになり、誤差が連鎖的に大きくなっていきます。この場合、学習が不安定になったり収束が遅くなったりするという問題が発生することがあります。
Teacher forcing
上記のSeq2seqの問題点を解消するための手法として、訓練時には常に正解の1時刻前の正しい入力を与えてあげるTeacher forcingという方法があります。
Teacher forcingによって学習されたモデルでは、Decoderの入力として与えられる系列は常に正しいものという前提で学習を進める振る舞いをするため、一度間違った単語が予測生成されてしまうとそこから単語の予測が狂いだす恐れがあります。
Scheduled sampling
Teacher forcingの問題を改善するための拡張手法です。
直前の時刻の予測で生成確立が最大となった単語を入力とする(シンプルなseq2seq)か、直前の時刻の正しい単語を入力とする(Teacher forcing)かを確率的にサンプリングして入力とします。学習初期はTeacher forcingの確率が高く、徐々に実際の翻訳テキスト生成時と近い状況としていきます。
BLEU
翻訳タスクの評価指標には、クロスエントロピーなどのタスク共通の指標に加えて翻訳専用のBLUEと呼ばれる指標が用いられます。
BLEUスコアは0~1の実数で表現され、値が高いほど良好な翻訳文であると判断されます。
式は以下の通りです。
は、翻訳文が参照訳より短い場合に与えるペナルティ(brevity penalty)であり、翻訳文より参照訳が長い場合は1となります。
Nには通常4が用いられています。
※ 機械翻訳自動評価指標の比較より
Transformer
再帰や畳み込みを用いずにAttentionという機構を導入することで時系列データに対応することが出来ます。

以降では、各モジュールの内容について説明していきます。
Positional encoding
Transformerは系列の処理にRNNを用いないため、そのままだと単語列の語順を考慮することが出来ません。
よって、入力系列の埋め込み行列に対して、Positional encodingで作成した行列を加算することで単語の位置情報を埋め込みます。
Masking
特定のkeyに対してAttentionの重みを0にするために使われます。
Transformerでは以下の2種類のマスクが定義されています。
- PADトークンに対するマスク
- DecoderにてSelf attentionを行う際に各時刻において未来の情報に対するAttentionを行わせないためのマスク
Attention
RNN系のネットワークでは長い系列を取り扱うと、時系列的に離れるにつれて指数関数的に情報が失われていくという難点がありました。
一方、Attentionは重み付け和として、どこに注目すべきかを情報として与えることで離れた情報を無理なく扱えるようになりました。
Self attention
queryとkey, valueすべてに同じ情報を用いるAttentionです。
Transformerモデル図では、EncoderおよびDecoderの下部において、queryおよびkey, valueに同じ系列の隠れ状態を取ります。
あらゆる位置同士の単語の関係性を重みにとることができるため、局所的な位置しか参照できない畳み込みを用いた手法よりも良い性能を発揮できると言われています。
Source target attention
queryとkey, valueとで別の情報を用いるAttentionです。
Transformerモデル図では、Decoderブロック中央のMulti-head attentionにおいて、queryはDecoderの隠れ状態、key, valueはEncoderの隠れ状態を取ります。
Scaled dot-product attention
queryベクトルとkeyベクトルの関連度を内積によって求めSoftmax関数を通してAttention weightを得ます。
Attention weightとvalueベクトルの内積によってquery中の単語とkey中の単語との関連性の強さをvalueベクトルに反映させることが出来ます。
Multi-head attention
query, key, valueを小さな複数のheadに分割し、それぞれでAttentionを行った後、concatします。
モジュール内部では、Masking, Scaled dot-product attention, Multi-head attentionが組み合わされています。
Add & Norm
学習およびテストのエラーを低減させるために、出力に入力(residual)を加算し、その結果を正規化します。
Position-wise feedforward network
全結合層、ReLU、全結合層の順で変換をかけていき、位置情報を保持したまま順伝播させます。
最後に
後半は演習問題がなく解説のみの内容になってしまいましたが、RNNが言語処理や音声処理、CNNが物体検知に繋がっていく様子が見えて面白い内容となりました。
今回の記事はここまで。Kazuki Igetaでした😃